A Language for Data Science Skills

Several years back now I developed the a chart for data science skills in research environments. Although it is broadly applicable in professional environments as well. It has helped me to think about the various levels of concern when teaching about the modern computation and data landscape.

Researchers often do not want to be IT or Computer Science professionals, they want to know just-enough computation to be able to do their science. Many researchers see the act of getting up-to-speed and smart in particular areas of computing and mathematics as taxes on their time. So that begs the question: how can we build a common taxonomy for data science skills that we can all relate to at some 30,000-foot view?
When we think about topics to teach, or where our gaps in knowledge are collectively, it is useful to consider the existing knowledge landscape of a learner. We can build a knowledge landscape with awareness and understanding as our axes. This particular grid was made famous by Donald Rumsfeld in a press conference in 2002.
Building this 2x2 grid of awareness and understanding (see below), we see there are things we know we know, and we understand them, this is what we typically think of when we think of knowledge. However there are three other nuanced areas in this knowledge landscape that are helpful when we think about building systems for enhancing knowledge among a community of people. Lets walk through each one, they can help us to lay the groundwork for how we can help more people understand what might be possible in a technology area:
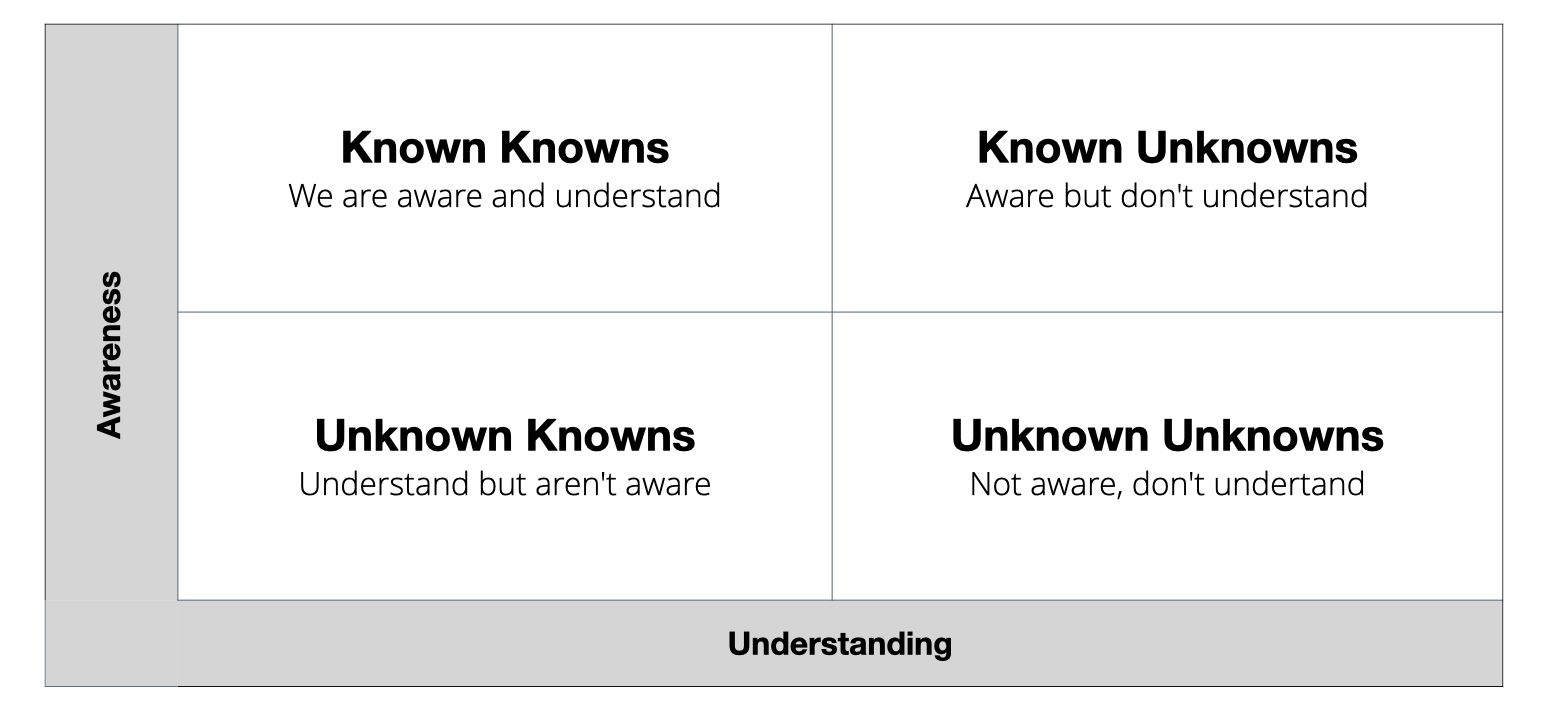
Known Unknowns – These are things we're aware of but don't really understand how they work. For example, maybe nuclear energy is a thing you're aware of, it has some interesting properties, but we haven't spent much time to understand how it works. It is important to society that we have known unknowns, where we know that others may fill in the understanding side of things. The name we have for the thing "nuclear energy" burries a whole boatload of complexity below it, but having the name we can reason about it in discourse without necessarily understanding it in-depth.
Known Knowns – These are the things we are coscious of knowing, skills, tallents, systems we feel we have a grasp for and understand the bevaiours and complexities of. This is where training and knowledge transfer often focuses in a traditional system. Often when we go off to become "trained" on a topic we're working toward mastery in particular skills so they can become known knowns.
Unknown Knowns – There are also things we understand, but aren't really aware of how we came to understand, things we have a "gut feel" for, we acknowledge we don't have a good process for how we know what we know in this area, this makes it very hard to teach others this knowledge. Being humans, as patterning animals, we have many of these where we've identified patterns, but don't necessarily understand underlying behaviours.
Unknown Unknowns – These are particularly dangerous when they become threats to our work or industries. These are the things that we don't even consider, think about. Things that are unknown unknowns to us mean that they're not necessarily considered possible.
This 2x2 matrix is important for us to consider as we consider ways to raise the level of collective understanding of any technology or tool. We can use it to build empathy for a potential learner by walking around the grid. What if we brought a plow, or gunpowder to a society where it was unknown/unknown, how would that be different than presenting it to a group or society in the other cells of the grid?
This "walk around" the knowledge awareness / understanding grid is what has lead to me creating the below chart for how data science skills, at a broad (what is "nuclear energy") level. As Data Science and computational thinking at a societal level matures, it is becoming more and more important that we have a taxonomy and language for how we relate to the differet levels of systems and their complexities. How we build a collective known, and spread the language of that known among more people. This makes it increasingly possible to reason about these known unknowns, and to build a map for teaching, and how to best help people bring them toward known knowns which can be beneficial to their research and work.
I've laid out the columns in the above diagram from left to right around how technical skills go from in-your head, to distributed across the global interconnected "hive mind" / "cloud". When we learn a new technical skill in the domains of compute, storage, software, workflow, or applied methods, we reason about them first at local, in our brain scale. We then translate these mental models to a physically present compute environment, our laptop or nearby workstation. If we outstrip the abilities of these compute environments, we need to build new models for compute-at-a-distance where we orchestrate and command distant compute resources in HPC our cloud environments. Then, if we need the globally distributed properties of computational clouds, we invest energy and time in exploring distributed paradigms where latency and discontinuous state become new challenges to how we relate to the environment.
Similarly in the landscape of interpersonal skills there is a set of skills that start relatively local in their impact and grow to broader and broader ranges of influence. As we think about what it looks like to be a professional practicioner of data science, in academia or industry, building this common language will be helpful for how we ineroperate and relate to one another in new working environments. Similar to how mathematical education has algebra, geometry, calculus, real analysis, vector calculus, differential equations, each of these topics has a broad consensus for what fits inside of them and what should be taught to a new learner of them. We do not have any kind of common language across data science and its environments yet.
This diagram isn't a prescription, or even an exhaustive enumeration of what to learn, but a broad landscape of the large themes that can help expand what the collective known unknowns are. This alone can help to accelerate both learning and implementation, based on a shared collective mental model.
It has been nearly three years since I first pulled this together, it has grown and gotten better from community input and comments. Does it still work? What's missing? Your thoughts, ideas, comments are welcome in GitHub Issues for the repository.
Member discussion